
Molecular Biology: From DNA to RNA to Protein
1 Protein Structure and Function
http://doi.org/10.2210/rcsb_pdb/mom_2021_7
Learning Objectives
The list of learning objectives below are what you should be able to do or know to prepare for problem solving.
Level 1 and 2 (Knowledge and Comprehension)
1.1 Draw the chemical structure of single amino acid and indicate the following features that are common to all amino acids: functional groups, side chains, and ionic forms.
1.2 Draw a dipeptide, tripeptide and identify the bonds (especially peptide bonds) and indicate the N- and C-terminal residues in peptides.
1.3 Classify each of the amino acid side chains on the carbon as basic, acidic, or as polar and charged, polar and uncharged, hydrophobic, or special.
1.4 Define and distinguish between the primary, secondary, tertiary protein structure. What forces hold together the secondary and tertiary structures?
1.5 Contrast the hydrogen bonding patterns that give rise to alpha helices with those that produce beta sheets.
1.5 Distinguish between tertiary and quaternary structure.
1.6 Differentiate between -sheet, -helix, and ‘random coil’ structures based on the atomic interactions involved on each.
1.7 List the types of interactions among amino acid side chains that stabilize the three- dimensional structures of proteins.
1.8 Describe the role that protein domains play within a protein’s three-dimensional structure.
Level Up (Application, Analysis, Synthesis)
1.8 Identify the role of disulfide bonds in protein folding and explain why secreted proteins often contain disulfide bonds.
1.9 Link the chemical structures of amino acid R groups to the types of interactions they could form in the folded structure of a protein and hypothesize the likely consequence of a mutation that swaps one amino acid for another.
1.11 Recognize secondary structure elements when proteins are represented in different ways (e.g. ball-and-stick structures, ribbon diagrams).
1.12 Explain the role that unstructured sequences play in protein function.
1.1 Introduction: Designer Proteins
The field of Protein Design uses a combination of machine learning, molecular biology and chemistry and is revolutionizing drug design. Using leaps made in computational power and artificial intelligence tools scientists can now predict how proteins fold based on knowledge of their amino acid sequence and create new designer proteins from scratch!
Let’s begin by first watching the following TED talk by Dr. David Baker in which he talks about this work and why it’s important to create new proteins. David Baker was awarded the 2024 Nobel Prize in Chemistry for his work on protein design along with Demis Hassabis and John Jumper, for protein structure prediction.
WATCH: TED Talk by Dr. David Baker.
Clink link above or watch video embedded below.
Why Proteins?
Why do we care about predicting protein structure? First, as mentioned in video, virtually everything that goes on inside cells happens as a result of the actions of proteins. Nature has programmed proteins to do nearly every job in the body:
- proteins catalyze the vast majority of cellular reactions (enzymes)
- proteins regulate traffic of substances in and out of cell (transport proteins)
- proteins allow for cell-cell communication and mediate responses to signals (signaling molecules, receptors)
- give structure both to cells (cytoskeleton)and to multicellular organisms and
- proteins exert control over the expression of genes.
- …. and much more!
Life, as we know it, would not exist if there were no proteins. Like many everyday objects, proteins are shaped to get their job done. Therefore, knowing the shape or structure of a protein offers clues about the role it plays in the body.
Second, proteins hold the key to developing new medicine. Most drugs ( injectable insulin, antiretroviral therapy for AIDs, Celebrex a drug to treat arthritis, allergies, blood pressure etcc ) target proteins. Therefore, knowing protein structure and then modifying it have been central to the development of lifesaving and life-altering medicines.
We begin by first looking at the building blocks of proteins and then how proteins adopt their three-dimensional structure (or fold). We conclude by briefly looking at methods that scientists use “see” or visualize three-dimensional structure of known proteins.
1.2 Amino acids are the building blocks of proteins
Cells use 20 amino acids to make polypeptides, although they do use a few additional amino acids for other purposes. All amino acids have the same basic structure, which is shown in Figure 1.1
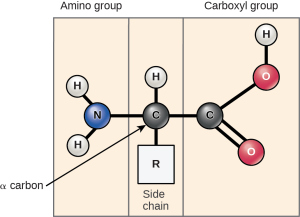
At the “center” of each amino acid is a central carbon atom called the α-carbon. (Alpha carbon)
Attached to the central carbon are 3 groups- a carboxyl group, an amine group, and a hydrogen atom which are common to all amino acids.
The fourth group is the R-group or side chain which provides each amino acid with its unique property.
With the exception of Glycine, which has an R-group consisting of a single hydrogen atom, all of the amino acids in proteins have four different groups attached to them and consequently can exist in two mirror-image forms shown below.
Like left and right hands that have a thumb, fingers in the same order, but are mirror images and not the same. If you superimpose your hands on one they are not identical. Similarly these two forms of amino acids have the same things attached in the same order, but are mirror images and not the same. The names given to two orientations stem from how they rotate plain polarized light and are called L- or D- amino acids.
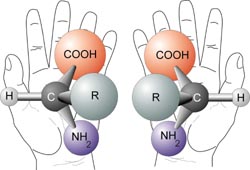
With only very minor exceptions, every amino acid found in cells and in proteins is in the L configuration.
Key Takeaway
The 20 amino acids have diverse properties which are determined by the chemistry of the side chains. Consequently, a polypeptide’s properties result from its linear sequence of amino acid residues.
NOTE: If you compare groupings of amino acids in different textbooks, you will see different names for the categories. Because there are some amino acids that cannot neatly be categorized into one or another you may also see sometimes the same amino acid being categorized differently by different authors, depending on where you look.
One grouping is shown in Figure 1.2 below.
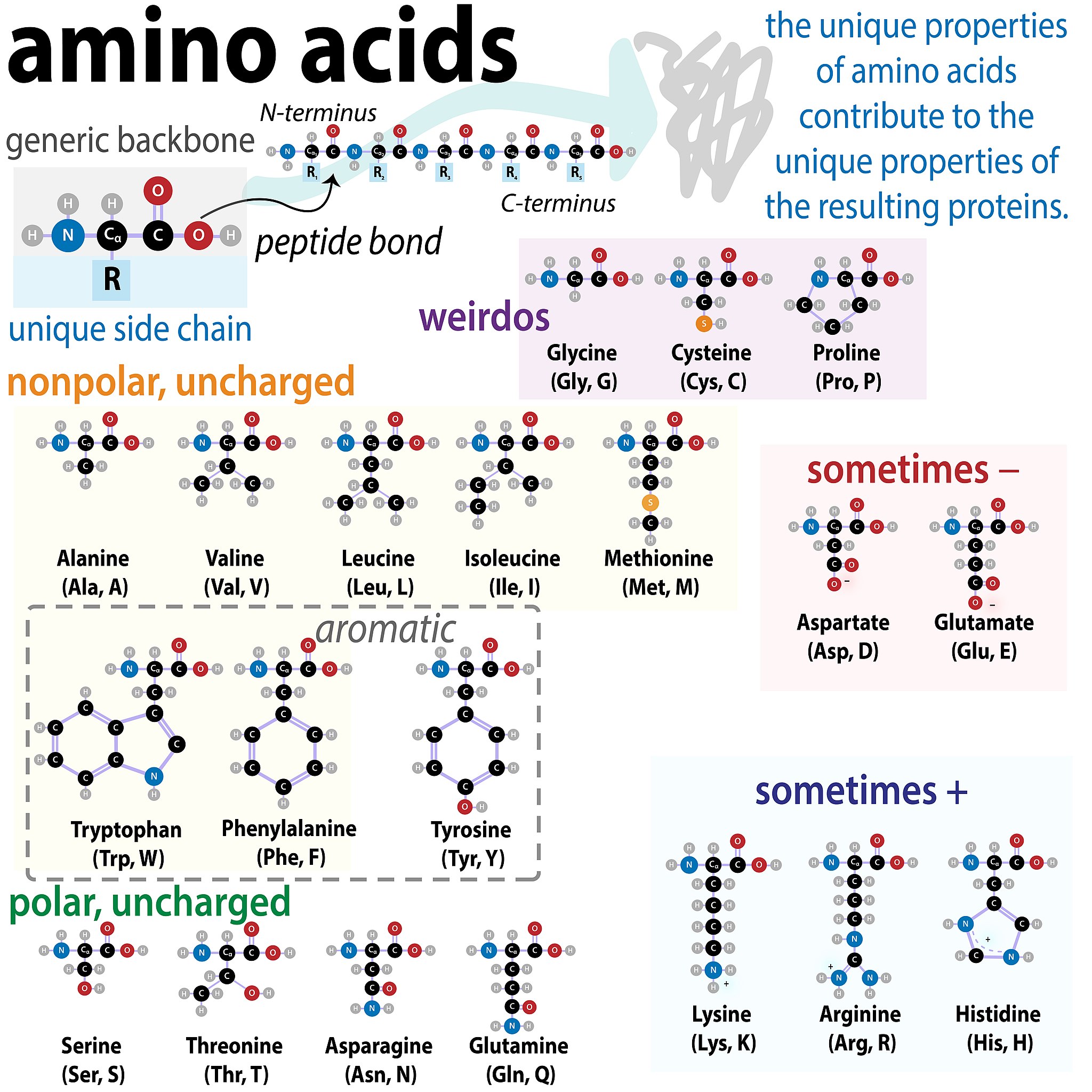 Figure 1.2 Amino Acid Chart. Image Credit: Biochemlife, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
Figure 1.2 Amino Acid Chart. Image Credit: Biochemlife, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
We will sort amino acids into four groups on the basis of the general chemical characteristics of their R groups:
1. Hydrophobic amino acids with non-polar R groups
2. Polar amino acids with neutral R groups
3. Polar amino acids with positive charged R group at physiological pH (~ pH 7.4)
(Note these are ACIDIC side chains since they have already lost a proton!)
4. Polar amino acids with negative charge R group at physiological pH
(Note these are BASIC side chains since they have already gained a proton!)
For the purposes of this course you do not need to memorize the structures of the amino acids. However, we will need to consider their chemical and physical properties to be able to predict how changes on amino acids within a protein can impact protein structure of function! See tip below for how to do this without memorizing.
TRY THIS
You should be able to infer the properties of the side chain from the 2D chemical diagram. You can do this without memorizing!
Study the amino acids in the figure above. We want to classify them as Polar Charged (+’ve , basic), Polar Charged (-‘ve, acidic), Polar Neutral, and Non-polar (Hydrophobic). Look at the R groups until you can see common elements in each category and then summarize what is common to the category.
What features did you look for?
Come up with the 3 simple “yes or no” questions you could ask based on your analysis to plug into the flowchart.
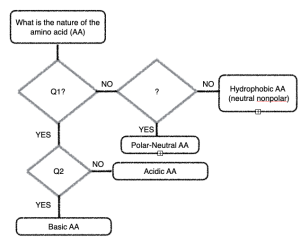
Hint: Think about the chemistry of acids and bases (what do the acidic side chains look like?), Think about what makes a covalent bond a ‘polar covalent bond?
Please see here for a refresher on Acid, Base, pH, and pKa. pKa may be a new term.
While most amino acids fall into the groups above there are three special amino acids, Glycine, Proline and Cysteine which stand apart from others with unique properties. We shall see what role these play in structure of proteins shortly.
1.3 Levels (Orders) of Protein Structure
We shall examine protein structure at four distinct levels (Figure 1.3): Primary, Secondary, Tertiary and Quaternary
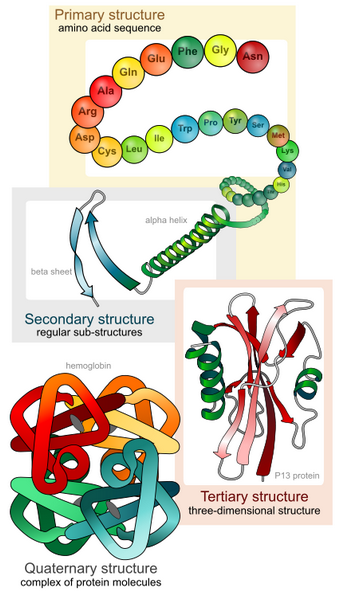
It is important to note that for each polypeptide the final 3-D shape or structure is its tertiary structure.
Quaternary structure refers to associations of two or more polypeptides, creating higher-order protein structures. Superimposed on these basic levels are other features of protein structure. These are created by the specific amino acid configurations in the mature, biologically active protein.
1.3.1 Primary Structure:
The specific order or sequence of amino acids in a protein is known as its primary structure.
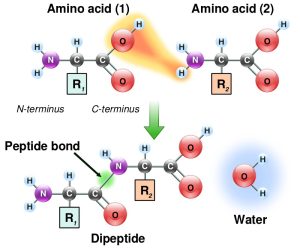
Individual amino acids are joined together by a covalent peptide bond formed between carbon of the carboxyl group of one amino acid and the nitrogen of the amino group of the other. The reaction results in removal of water. (Figure 1.4)
Recall that this is a condensation reaction or dehydration reaction that is common in the making of all biological polymers.
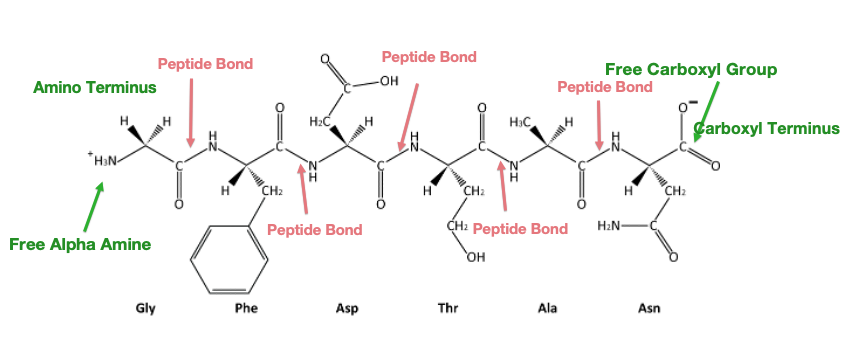
Study the image of a partial polypeptide below in Figure 1.5.
Notice that it has the repeating structure -N-C-C-N-C-C- which forms a polypeptide backbone. The amino acids side chains end up on opposite sides of the backbone.
Note that polypeptides have a ‘polarity’ because they always have a “free” amino end and “free” carboxyl end.
The ends of the polypeptide are therefore called the amino- or N-terminus and carboxyl- or C-terminus. During translation, the ribosome adds subsequent amino acids to the C-terminus of a growing polypeptide chain, so we say that translation proceeds from the N- to C- terminus.
Consequently, since proteins are synthesized starting with the amino terminus and ending at the carboxyl terminus, therefore by convention amino acid sequences are also written left to right from amino to carboxy-terminus.
The name of the N-terminal residue is always the first amino acid. The name of each amino acid then follows. Reversing the directionality indicates a very different protein sequence!
It is the order of amino acids (and thus primary structure) that dictates the 3-D conformation (shape) the folded protein will have.
Jargon/Terminology Alert!!
Amino acids that are part of a protein are referred to as ‘amino acid residue(s)’ or sometime just “residue”.
You will read and hear this term utilized often. For example “The protein insulin consists of X amino acid residues” or “The Glycine residue was mutated to Alanine”.
Practice Exercises
1.3.2 Secondary Structure
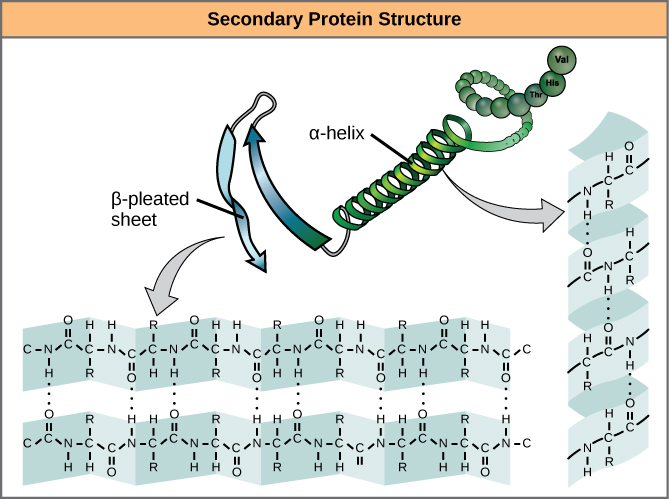
As protein synthesis progresses, interactions between amino acids close to each other begin to occur, giving rise to local patterns called secondary structures. Two common types of secondary structures in proteins are alpha (α) helices and beta (β) strand/sheets. (Figure 1.6)
Both of these structure form due to the spontaneous formation of hydrogen bonds between amino groups (NH) and oxygen (CO) of the peptide bond ( polypeptide backbone )
α-helix
In the α-helix, hydrogen bonds form between C=O groups of one peptide bond and N-H group of another located four amino acids away.
Visualization:
In cartoon representations of protein structure α-helices are depicted as coils or ribbons.
β strand versus β-sheet
A flattened or nearly completely extended form of the helix is a β- strand. These have bends that are sometimes referred to as pleats, like the pleats in a curtain.
A β sheet is formed when two or more β strands lying next to one another are connected through hydrogen bonds. As multiple strands from different regions of a polypeptide interact in this way a relatively flat, sheet-like surface is created hence the term β sheet.
Visualization:
In cartoon representations of protein structure β strands are depicted with broad arrows pointing in the direction of the carboxyl-terminal.
Loops and Turns
Segments of the peptide backbone that do not form secondary structures are called loops and turns. Loops are turns are necessary to allow a polypeptide to change direction as it folds into its final shape. Loops and turns are almost always found on the surface of the protein. Because they are on the surface of a protein, the amino acids are often involved in interaction with other proteins or the environment.
Loops are shown in cartoon representations as lines connecting regions of secondary structure.
Key Takeaway
Secondary structures arise due to hydrogen bonds between peptide bonds. Note: Thus far, the amino acid side chains (R groups) have played no role in establishing secondary structure.
1.3.3 Tertiary Structure
For all proteins, the unique final three-dimensional structure adopted by the polypeptide is its tertiary structure.
This structure is determined by non-covalent interactions between R groups and/or between R groups and polypeptide backbone interactions.
Some of the non-covalent interactions include:
Ionic interactions (strongest): between pairs of charged amino acids also known as salt bridges.
Hydrogen bonds: between polar groups- one of these polar groups is acting as a hydrogen donor the other as a hydrogen acceptor.
van-der Waals interactions (weakest): act only over short distances although they are present between any pair of atoms in close proximity.
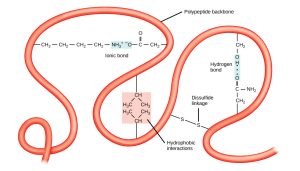
Proteins fold in an aqueous environment, and that environment is critical to how the proteins adopt their native conformation.
Hydrophobic molecules do not form strong bonds with water. In aqueous solutions, hydrophobic molecules are driven together to the exclusion of water.
Thus amino acids with hydrophobic side chains are buried in the interior and charged polar amino acids are often on the surface.
What about the polarity of the peptide bond or polypeptide backbone which includes NH and CO groups?
Those are already buried due to the H-bonds formed to create secondary structures!!
Disulfide bonds stabilize tertiary structure
Tertiary structures are strong simply because of the large numbers of non-covalent interactions that form them. However, one covalent bond is possible and is formed when two cysteine amino acids (sulfhydryl-containing side chain) are close together as a result of tertiary structure formation.
The sulfhydryl group is highly reactive and will covalently bond with another sulfhydryl group to form a covalent disulfide bond (the disulfide (–S-S-) bond).
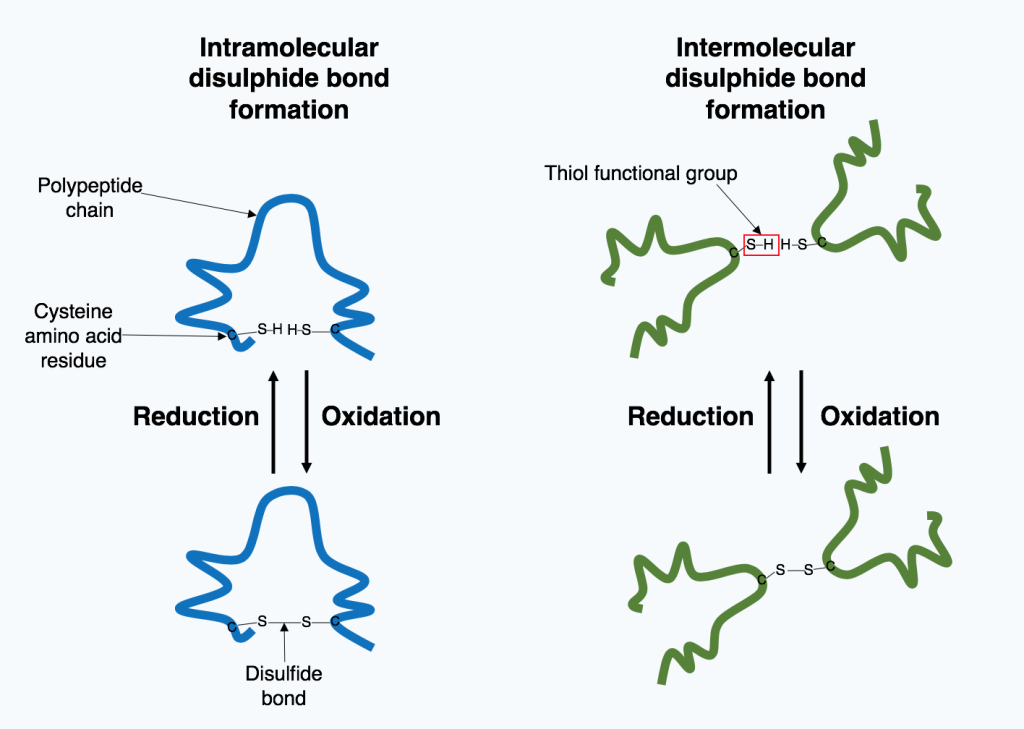
The formation of this bond depends on the environment. Oxidizing environment favors bond formation. Reducing environments break disulfide bonds.
Disulfide bonds are crucial to the active protein. Imagine how changes in temperature or ionic strength would disrupt noncovalent bonds required for the correct 3D shape of the active protein. Unaffected by such changes, disulfide bridges limit the disruption and enable proteins to refold correctly when conditions return to normal (think homeostasis!)
Did you know?
All of the interactions, weak and strong, determine the final three-dimensional shape of the protein. When a protein loses its three-dimensional shape, it is usually no longer be functional, and said to be denatured. Heat, high salts and reducing agents all contribute to denaturing a protein.
1.3.4 Quaternary Structure
Many Proteins operate as larger complexes. The assembly of more than one polypeptide into a protein complex is the quaternary structure. This can mean as few as two small polypeptides, or an assemblage as big as the nuclear pore or — even bigger — silk or human hair. We will encounter several molecular machines (example DNA polymerase, RNA polymerase) that are comprised of more than 10 different polypeptides.
The polypeptides can be identical to each other or can be different polypeptide chains. The stabilizing interactions that hold the multiple polypeptides together are the same non-covalent interaction interactions (hydrogen bonding, ionic bonding, and hydrophobic interactions) and covalent disulfide bonds, that stabilize the tertiary structure. Except, that they occur between polypeptides.
The individual polypeptides that make up the larger structure are often referred to as subunits. The nomenclature used for such multi-subunit proteins reflects the number of polypeptides and the similarity between them.
For example, Estrogen (the hormone) receptor consists of two identical polypeptides coming together to form a functional protein. This is called a homodimer. [ homo (similar) di (two) mer]
Adult hemoglobin is composed of four polypeptides – Two polypeptides called α and two polypeptides called β. Proteins with multiple polypeptides where at least one of the polypeptides is different from the other are Heteromers. Hemoglobin would be a hetero-tetra– mer.
Confusing Terminology: Polypeptide versus Proteins
We use the term polypeptide to refer to a single polymer of a long stretch of amino acid. A polypeptide is the translation product of one gene. It may or may not have folded into its final, functional form.
The word protein is commonly used interchangeably with polypeptide. For example, we often say “Protein” synthesis. It is generally used, however, to refer to a folded, functional molecule. As we have just seen however a protein may be made up of more than one polypeptide.
For example, Hemoglobin is a protein– but it is made up of 4 separate polypeptides that come together to adopt a final shape.
Practice
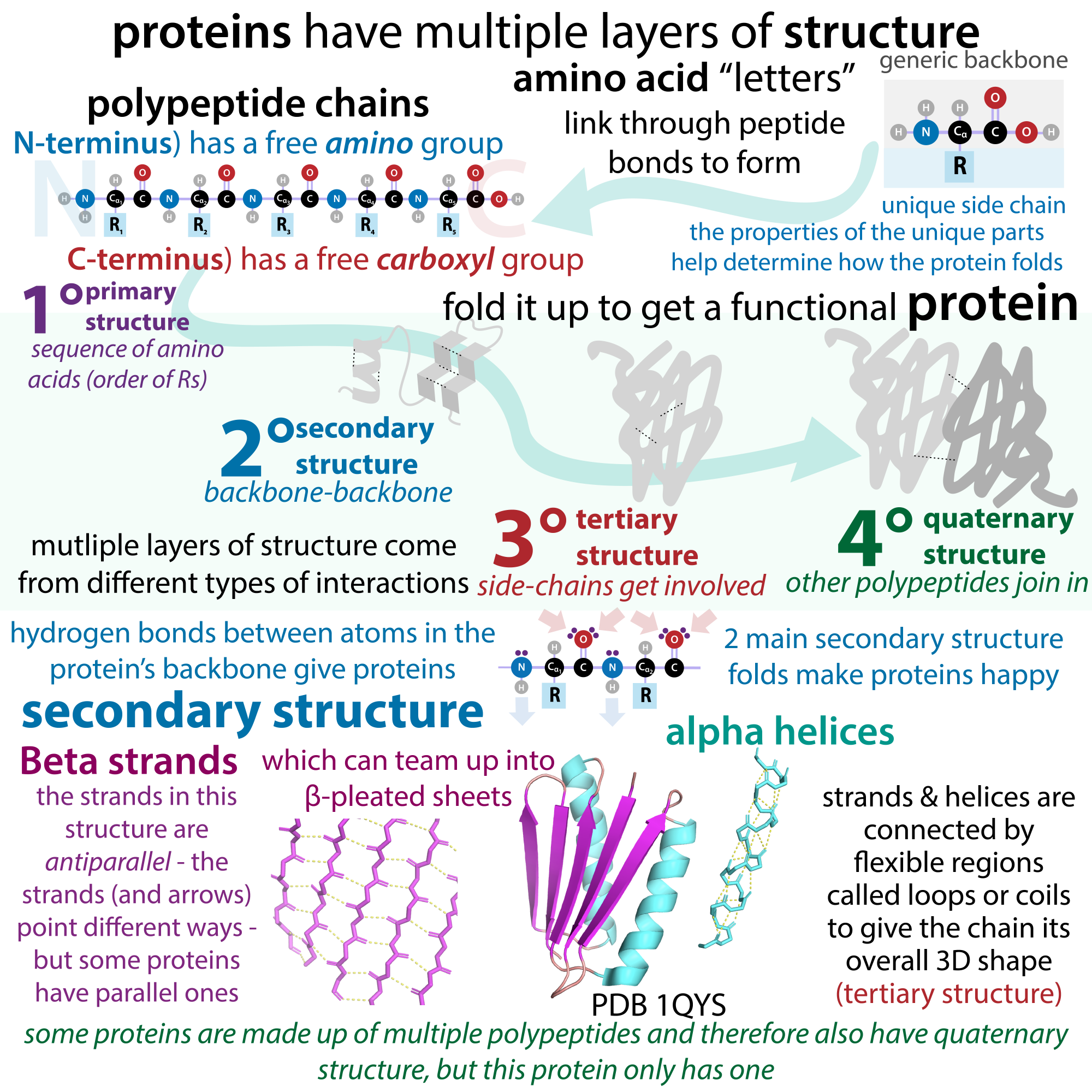
Summary: Via Sketchnotes!
A great learning tool is to create concept maps that highlight the key terms and connect them to one another in meaningful ways.
Included is an example of a graphic organizer created by a young scientist. You can find her delightful work here: “the bumbling biochemist”:https://thebumblingbiochemist.com/.
Making one for yourself makes for better learning than memorizing one. You don’t have to be an artist to do this!
Image attribution: Biochemlife, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
1.4 Protein Structure Deep Dive
Features of Alpha-Helices and Beta Sheets
Shown below is a diagram for the alpha-helix highlighting the key features of the helix. (Figure 1.10)
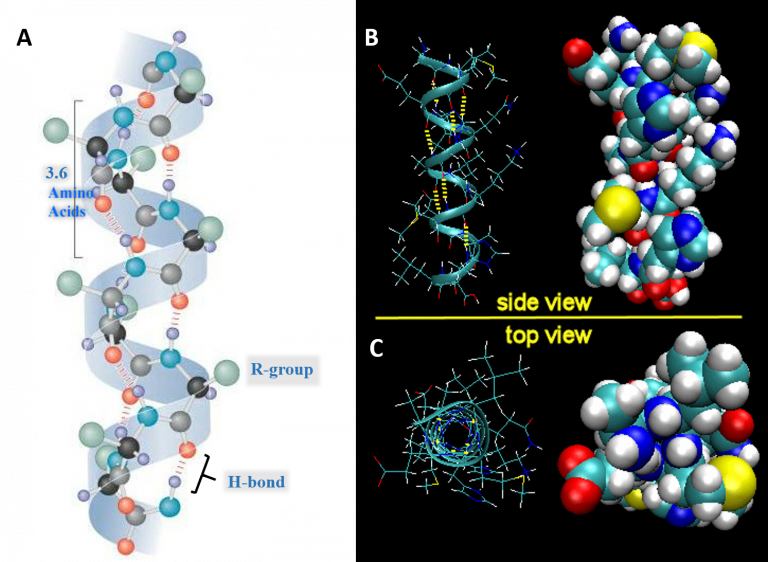
- Each full turn of the helix (360°) is 3.6 amino acids in length.
[Note that the H-bond forms between C=O groups and N-H groups in the polypeptide backbone that are four amino acids distant]
- Helices are predominantly right-handed.
- The hydrogen bonds are parallel to the axis of the helix, located inside the helix and are in a regular arrangement. [All C=O bonds point in one direction, all N-H bonds point in opposite directions].
- R-groups extend away from the helix.
The stability of an alpha helix is affected by different factors.
- Amino acids whose R-groups are too large (tryptophan, tyrosine) or too small (glycine) destabilize α-helices.
- Glycine has a lot of conformational flexibility given its side chain is simply an H atom! Glycine is found in the more flexible regions of proteins which are the loops.
- Certain combinations of adjacent amino acids. For example, a run of positively charged or negatively charged side chains will repel one another.
- Presence of Proline- the ‘helix breaker’.
- Take a look again at the side chain of the proline in Figure 1.2.
- Notice that the hydrogen connected to the N of the amine group is not available to hydrogen bond! In fact, proline disrupts both types of secondary structures. However, proline is commonly found in turns or loops between the beta-strands, connecting secondary structure elements, and occasionally in the first helical turn where the side chain geometry does not create a problem.
Parallel and Antiparallel β-Sheets
In a β-sheet, two or more sections of the polypeptide run alongside each other and are linked in a regular manner by hydrogen bonds between the main chain C=O and N-H groups.
Take a look at the orientation of the strands in the image below. In parallel beta sheets, the arrows indicating the N-C direction are the same, whereas in antiparallel sheets adjacent strands are in opposite directions.
Notice how the H- bonds are angled or slightly bent in the case of parallel beta sheets, versus the more straight bond in between adjacent strands in antiparallel sheets.

Practice Exercises
1.5 Domains in Protein Structure.
An important concept in protein structure is that of the protein domain. A domain is an element of the protein’s overall structure that is stable and often folds independently of the rest of the protein chain. Since the shape is important for function, domains have a shape that is best suited for a particular cellular function and are named accordingly!
For example; Nucleotide-binding domain, Calcium-binding domain, DNA binding domain. Occasionally they are named after their discoverers like Pleckstrin Homology (PH) domain.
Figure 1. 10 shows structures of two different proteins both of which have the PH domain.
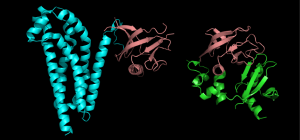
Proteins that have this domain, can a bind a molecule of phosphatidyl-inositol triphosphate that is generated as part of a common cell-signaling pathway.
It not uncommon to find a single polypeptide containing two or more physically distinct domains, each performing a specific task.
For example we will encounter proteins important for transcription called Transcription Activators. As the name suggests we can deduce that these proteins ‘activate’ transcription. These proteins have two distinct domains that allow the protein to carry out its job- one of which is DNA binding (which is needed for transcription!), the other activation domain.
Because domains can fold independently and are stable, a common tool used in genetic engineering is to create chimeric proteins with novel functions by combining domains together.
1.6 How Proteins Work
Proteins have unique shapes which are suited for a their function and a proteins shape is dictated by the specific amino acid sequence.
While proteins have a wide variety of functions, all proteins work by recognizing specific chemical entities, and ‘bind to ‘ or interact with them. The binding partner may be an ion, other small molecules or large macromolecules like another protein. A key aspect to this interaction is it’s specificity. That’s it! Proteins stick to specific things.
For example:
Enzymes, the most commonly studied type of protein, binds to unique substrates to catalyze a chemical reaction, and they stick to transition states more tightly.
Antibodies, bind with great specificity to specific pieces of bacteria, or viruses called antigens! A very useful feature in Molecular Biology methods!
Signaling molecules, like hormone receptors (Insulin receptor, Estrogen receptor) bind specifically to hormone or signal (Insulin, Estrogen).
The enzymes and proteins involved in mediating molecular biology processes of life (Replication, Translation and Transcription) recognize and stick to specific DNA or RNA sequences.
The 3-D shape provides or results in the special binding pocket, or cavity on the surface of the protein, often called the binding site.
The binding interaction utilizes all the various non-covalent interactions between side chains of amino acids that are exposed and the binding partner.
Protein Modifications can affect structure and function
Proteins in the cell are often modified post-translationally by the addition of functional groups via covalent bonds to the side chains of amino acids. These groups are added by enzymes. Think of these modifications as an additional makeover or accessorizing the protein.
We have spent time revealing how the nature of the amino acid is crucial for protein folding, and the final shape is important for function. Therefore, changing key amino acids chemically can impact the structure and the function. The changes in shape are often subtle but can have a dramatic impact on function, activity, stability, localization, and/or interacting partner molecules.
Three modifications that we will encounter in this course include:
- Addition of phosphate groups (phosphorylation) to Serines, Threonines and Tyrosines
- Addition of acetyl groups (acetylation) to Lysines
- Addition of methyl groups (methylation) to Lysines, Arginines.
Other types of modifications are shown in the diagram below (Figure 1.11).
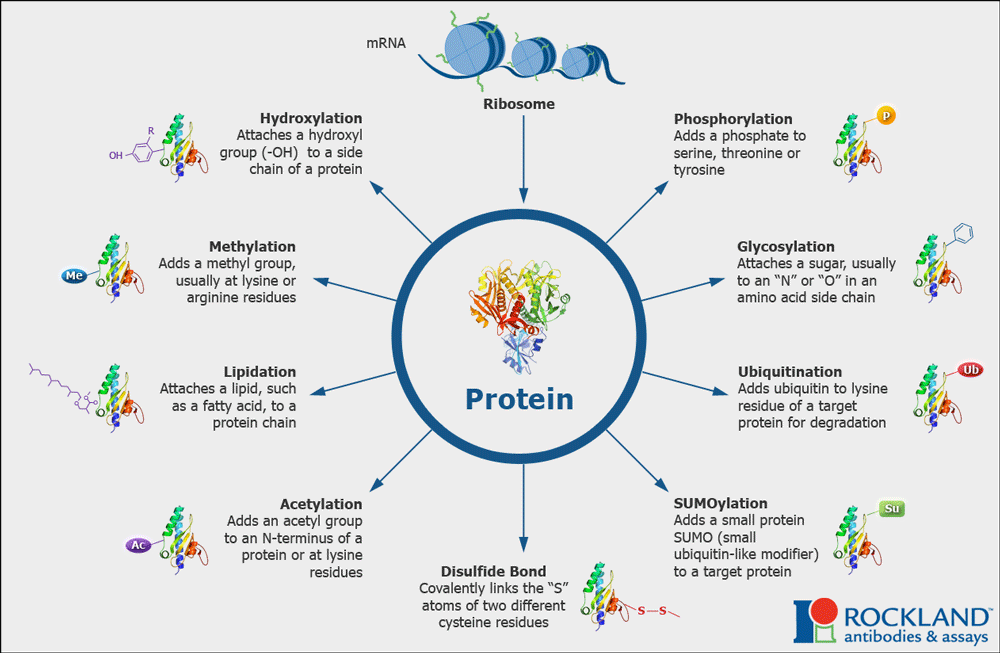
Collectively these modifications account for and enhance the molecular and functional diversity of proteins within and across species. Much of the work of proteins inside cells involved signaling or communication.
Often these modifications are reversible! Meaning that just as there are enzymes that add these groups, there are enzymes that can remove them. Having reversible modifications allows many proteins to function as signaling nodes: turning on (when modified) or off (when modifications are removed) or vice versa!
1.7 Intrinsically Disordered Proteins
We have thus far focused on how proteins can adopt very specific three-dimensional shape. However, we now know of an entire classes of proteins called Intrinsically Disordered Proteins that lack fixed or ordered three-dimensional structure under physiological conditions. The spectrum of ‘disorder’ in this class of proteins range from disordered regions, partially structured, random coils.
What is the significance of intrinsically disordered proteins or regions? The fact that this property is encoded in their amino acid sequences suggests that their disorder may be linked to their function. The flexible, mobile nature of some IDP regions may play a crucial role in their function and disordered proteins transition to a folded structure upon binding a protein partner or undergoing post-translational modification. The same protein can adopt a different structure based on the binding partner and can adopt different functions.
Other examples, regions of a single protein that is disordered may enhance the ability of proteins like the lac repressor to translocate along the DNA to search for specific binding sites.
1.8 Visualizing Protein Structure
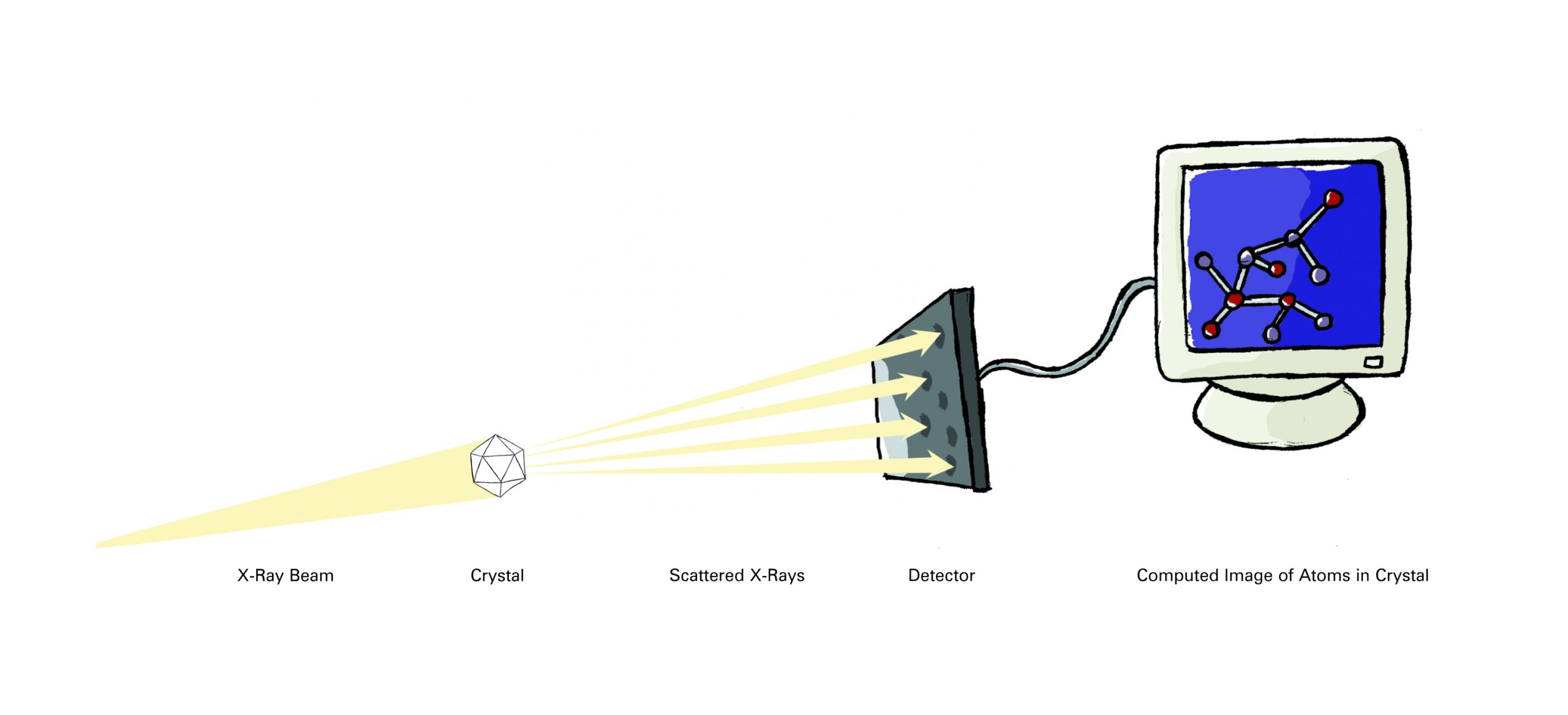
How would you examine the shape of some thing too small to see in even the most powerful microscope? The two most common methods (prior to computational methods of protein prediction) used to investigate molecular structures are X-ray crystallography (also called X-ray diffraction) and nuclear magnetic resonance (NMR) spectroscopy.
Researchers using X-ray crystallography grow solid crystals of the molecules they study. Those using NMR study molecules in solution. Each technique has advantages and disadvantages. Together, they provide researchers with a precious glimpse into the structures of life.
More than 85 percent of the protein structures that are known have been determined using X-ray crystallography. In essence, crystallographers aim high-powered X-rays at a tiny crystal containing trillions of identical molecules. The crystal scatters the X-rays onto an electronic detector like a disco ball spraying light across a dance floor. The electronic detector is the same type used to capture images in a digital camera. After each blast of X-rays, lasting from a few seconds to several hours, the researchers precisely rotate the crystal by entering its desired orientation into the computer that controls the X-ray apparatus. This enables the scientists to capture in three dimensions how the crystal scatters, or diffracts, X-rays. The intensity of each diffracted ray is fed into a computer, which uses a mathematical equation called a Fourier transform to calculate the position of every atom in the crystallized molecule.
The result — the researchers’ masterpiece — is a three-dimensional digital image of the molecule. This image represents the physical and chemical properties of the substance and can be studied in intimate, atom-by-atom detail using sophisticated computer graphics software.
Depictions of Biological Molecules
The data generated by experimental methods generates mathematical models of where atoms within a molecule is in 3-D space in relation to others. Scientists have devised an artificial way of representing them, each of which highlights different aspects of protein structure.
Watch the video below that highlights the conventions of representing biological molecules.
https://youtube.com/watch?v=887OdJWadn8%3Fsi%3DNdYxp3Eh-mMjAFFF
A free resource, the Protein Data Bank hosts experimentally determined 3D structure information of proteins, nucleic acids, and complex assemblies. These help students and researchers understand all aspects of biomedicine and agriculture, from protein synthesis to health and disease.(1)
WATCH: Celebrating 50 Years of the Protein Data Bank Archive
Structure Based Drug-Design
We end this chapter back where we started. While there is a new era of learning how to make new proteins from scratch, the development of new drugs that bind to existing proteins remains a powerful tool.
Using tools and visualization methods discussed above scientists use computers to design compounds that can fit a particular binding site and/or make informed decisions about which amino acids to alter to modify or inactivate proteins.
Explore PDB Structures
This part of your pre -class work is designed to introduce you to the Protein Data Bank (RCSB PDB) (https://www.rcsb.org/).
Please spend some time to familiarize yourself with what information is archived in this data bank and how it is presented to the users, you will use PDB to explore insulin structure and think about drug design.
WATCH: Video “Exploring PDB Structures in 3D with MolStar (Mol*): Introductory Guide”. You can stop at time stamp 5:02
Use link: https://youtu.be/EdgmALgbJpM
Remember to:
- Watch the videos that go over the key takeaways of the material above.
Complete the problems related to this chapter.
References and Attributions
(1) The Protein Data Bank H.M. Berman, J. Westbrook, Z. Feng, G. Gilliland, T.N. Bhat, H. Weissig, I.N. Shindyalov, P.E. Bourne (2000) Nucleic Acids Research, 28: 235-242. https://doi.org/10.1093/nar/28.1.235
This chapter is curated from and contains material from the following CC-licensed content. Changes include rewording, replacing, and removing paragraphs with original material. Please cite this book along with the information below.
- Section 1.1 and Section 1.8 from Structure of Life (2007). Booklet, retrieved from National Institute of General Medical Sciences https://www.nigms.nih.gov/education/Booklets/The-Structures-of-Life/Pages/Home.aspx.; (United Stated Government Work, in the public domain)
- Ahern K, Rajagopal I and Tan T. (2013). Biochemistry Free for All (Version 1.3). Licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.The entire textbook is available for free from the authors at http://biochem.science.oregonstate.edu/content/biochemistry-free-and-easy.
- Details of Protein Structure” by Gerald Bergstrom, LibreTexts which is licensed under CC BY. The chapter can be found online at https://bio.libretexts.org/@go/page/16428
Images
Unless otherwise noted within the text, images on this page are licensed under CC-BY 4.0 by OpenStax. Located at: https://openstax.org/books/biology/pages/3-4-proteins.Access for free at https://openstax.org/books/biology/pages/1-introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}